Update #1: I recently run in a situation with my Wacom that everything failed. So I uninstalled everything first.
- Open your Application folder, and locate any of the following folders:
- Bamboo
- Pen Tablet
- Tablet
- Wacom
- Wacom Tablet
- In each of these located folders will be a Wacom Utility, double-click to launch the utility
- Select the option to ‘Remove’ in the ‘Tablet Software’ section of the utility
- You may be prompted to enter your system’s password at this time
- The utility will notify you when the removal is complete
I use a Wacom table instead of a mouse. Most designers do. That driver has a mind of its own. It crashes a lot.It’s happens when I startup Illustrator or switch workplace or when it wakes up from sleep mode or connect to an external monitor.Or just randomly.And I don’t want to restart my computer every-time it happens.So I googled the problem before I dive into the problem myself.The post describes the same problem, but the solution doesn’t work for me.So this is my solution.First the specs:
- Mac OS 10.12.3
- Wacom Bamboo model CTH-470
Make sure you have the correct driver installed… duh! In a working situation (driver is working) you can see it with “Activity monitor”, search for “PenTabletDriver”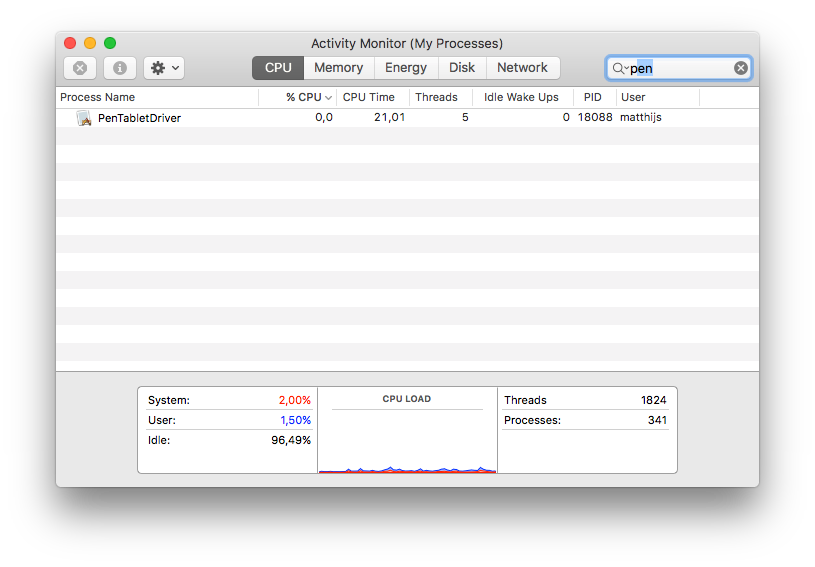 So when your Wacom is not working you won’t see it (obviously).
So when your Wacom is not working you won’t see it (obviously).
Now how to restart it!
Now open the Finder > Go > Go to folderAnd copy past this folder:/Library/Application Support/Tablet/It will open een folder with “PenTabletDriver.app” in it.Double click it and you Wacom will work again.
Developers Solution
In the comments of earlier mention blog, someone mentions a “Automator script”.I will be using bash: create a file named “WacomReboot.sh”#!/bin/bashecho 'Kill the PenTabletDriver (just to be sure)'killall PenTabletDriverecho 'Start the PenTabletDriver again'open -a PenTabletDriver & exitSave file in /usr/local/bin/Now restart the Wacom:Open terminal and type “WacomReboot.sh” and enter:→ WacomReboot.shKill the PenTabletDriver (just to be sure)Start the PenTabletDriver againBam … back to work!





